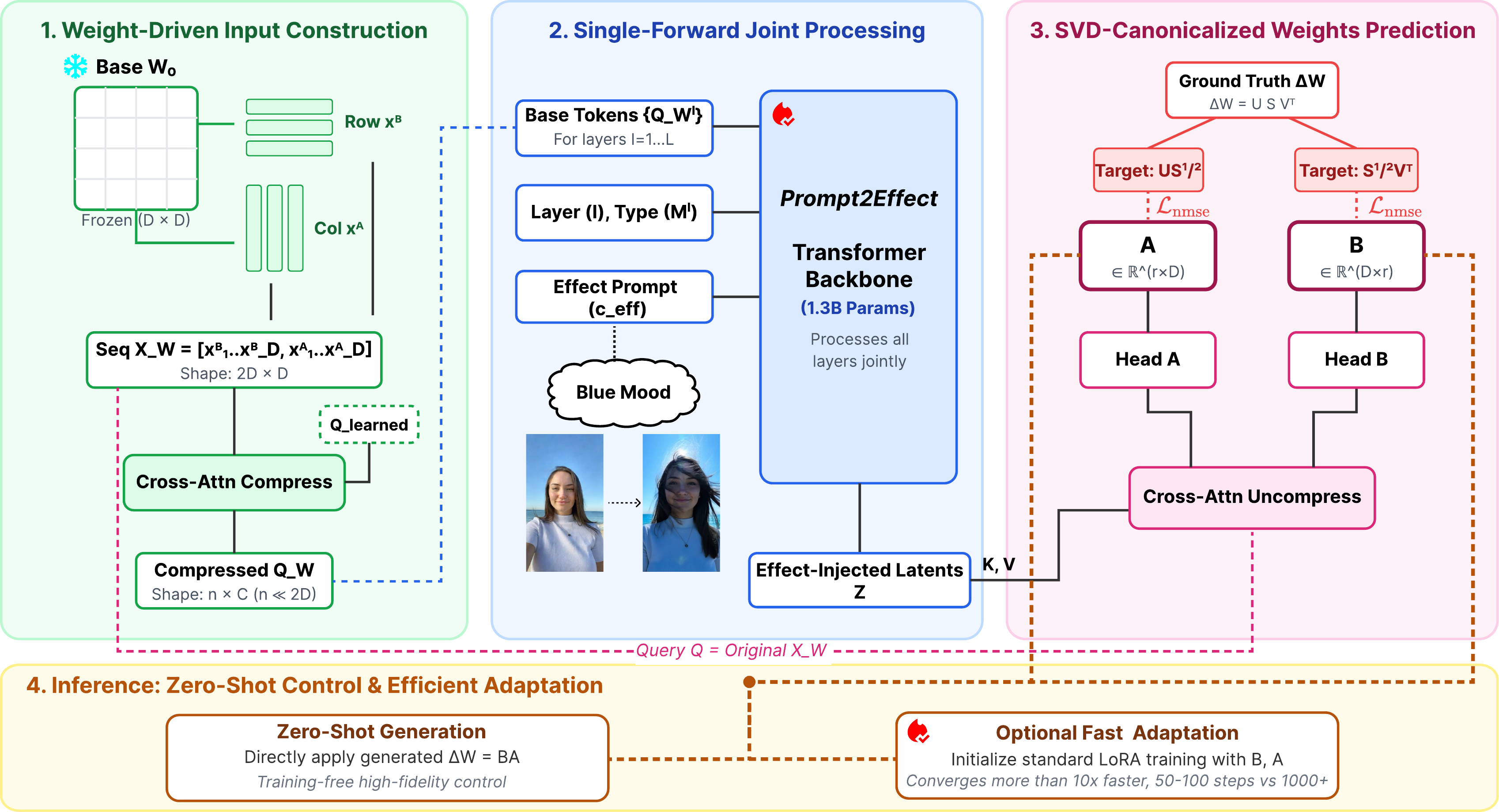
Hypernetwork design. A modular per-block design with separate small predictors (“Ensemble”) underperforms our unified 1.3B-parameter hypernetwork, which models all layer weights jointly — indicating that global coordination across layers matters for consistent effect synthesis.
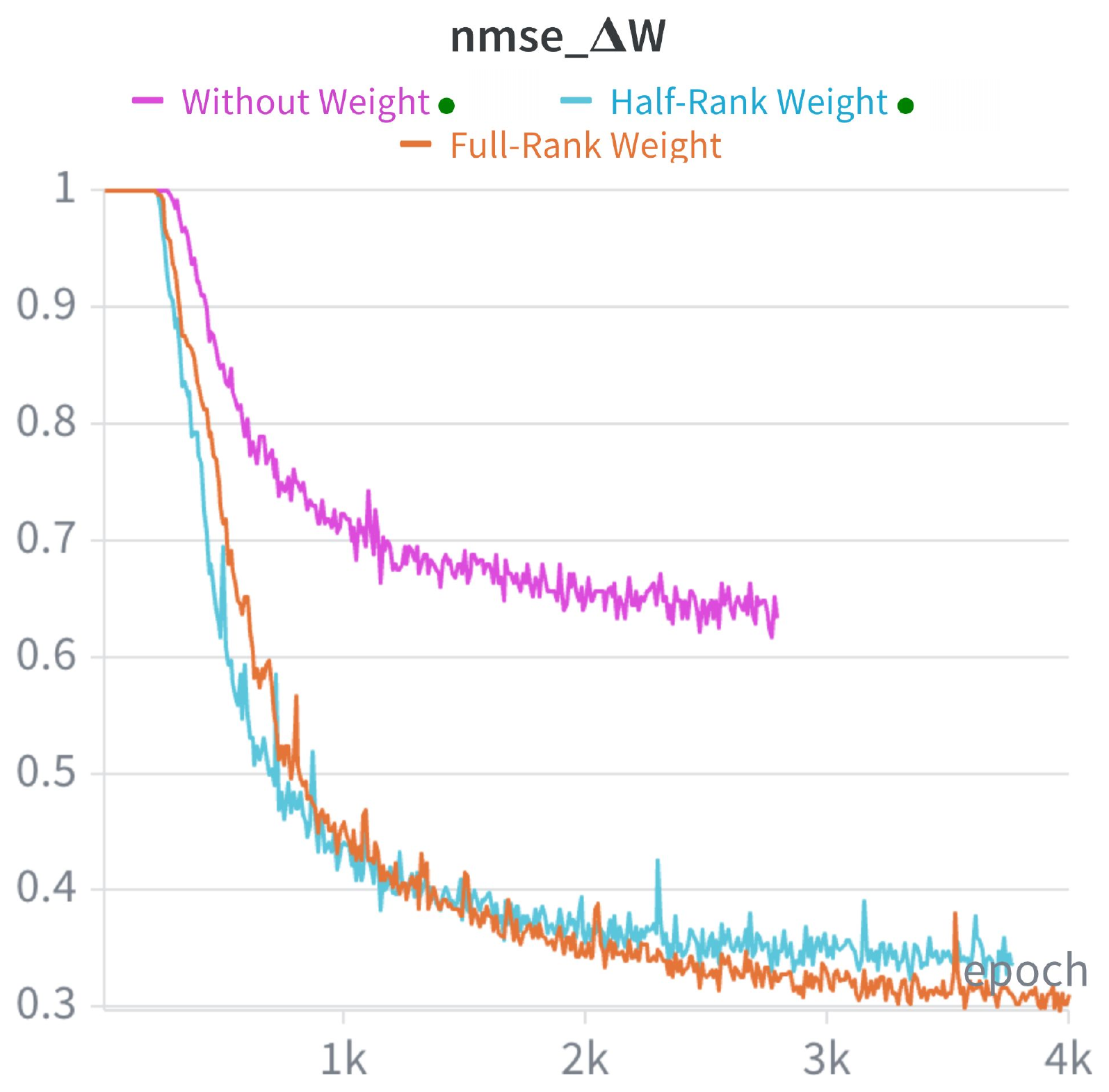
Weight-driven input. Replacing the weight-driven input with abstract noise embeddings (“Noise”) causes a steep drop in VLM metrics and aesthetic quality: mapping text directly to functional weights is hard without structural priors. Exposing the hypernetwork to the principal subspaces of the base weights is crucial, and full-rank tokenization works best.
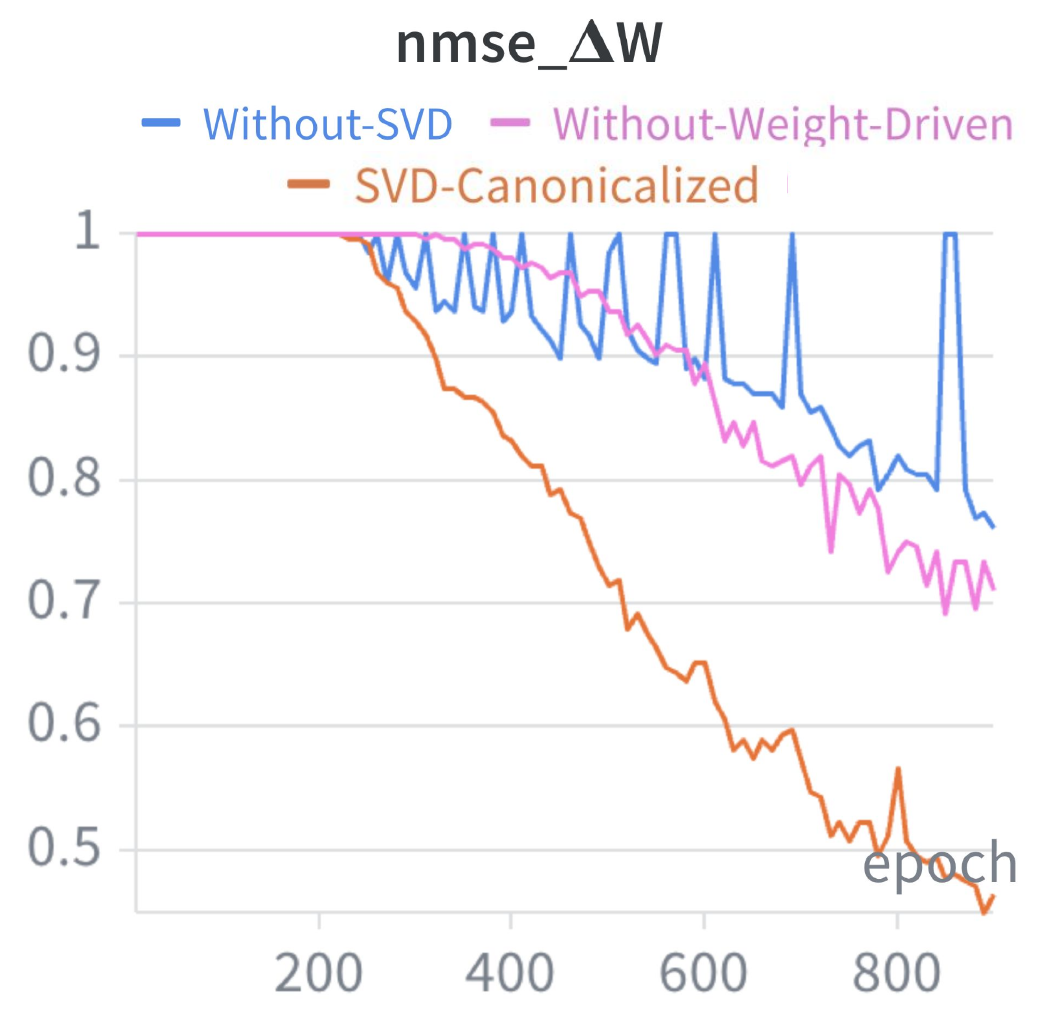
SVD-canonicalized prediction. Predicting SVD-canonicalized targets (A★, B★) rather than raw LoRA matrices accelerates convergence and improves stability: the NMSE of the reconstructed ΔW decreases smoothly, whereas the non-canonicalized variant oscillates and converges to a substantially higher final error.
Compression ratio. Among learned-query counts for weight-token compression, n = 256 gives the best compute–fidelity trade-off, outperforming n = 128 and marginally improving over n = 512.